I have obtained experimental data: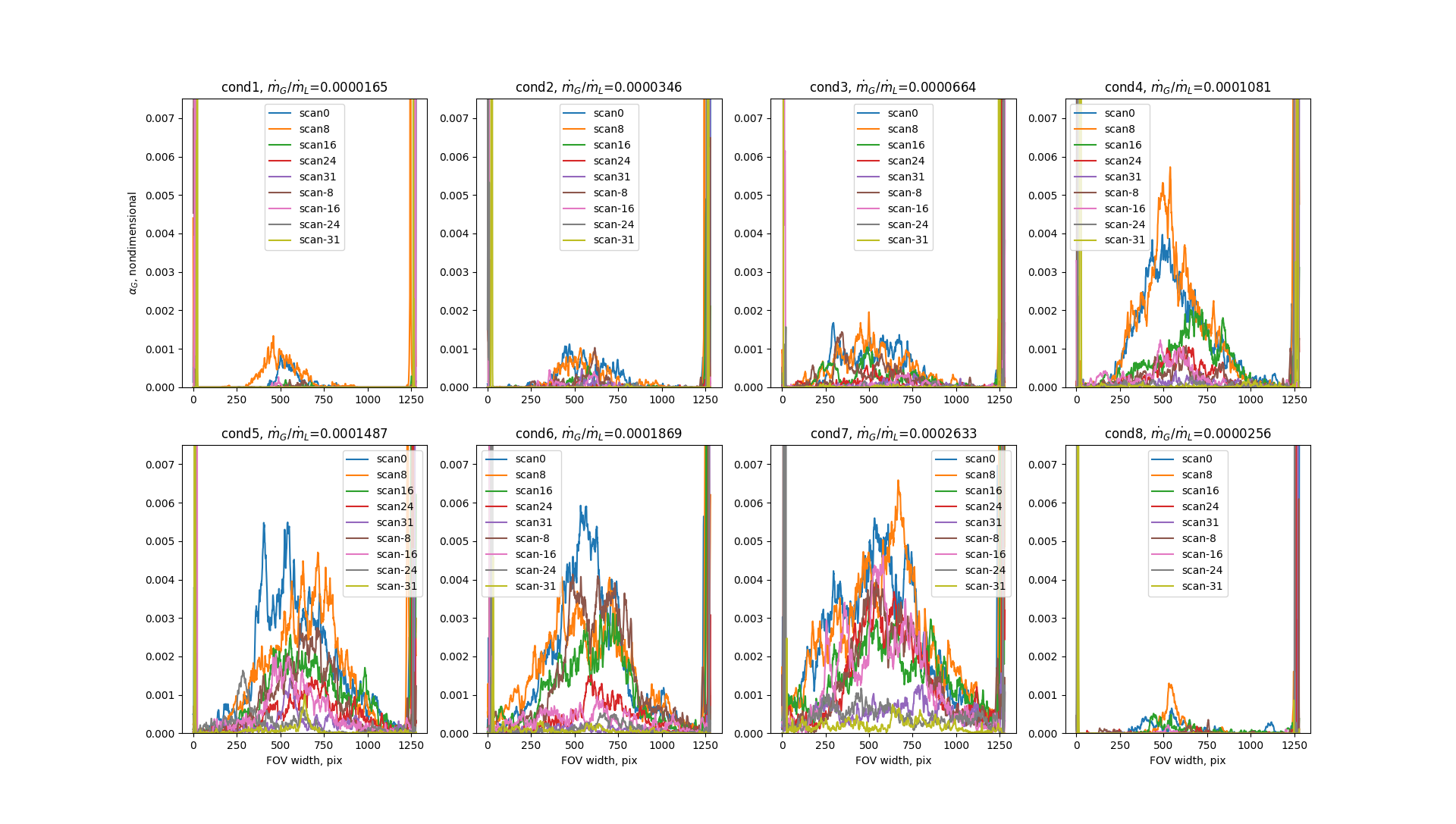
Those "horns" (leftmost and rightmost peaks) in each image are outliers.
Is there a statistical method that can identify those "horns" as outliers?
__________
_Possibly useful clarifications._
1) The data is the distribution of white pixels along the horizontal axes of binarized images. Since I did the experiments I do know that those "horns" are outliers.
2) I would like to automate outliers identification and removal because I will have way more data like this.
3) The immediate left and right vicinity of each horn contains "good" data points (i.e. not "outlying" data points). Thus, I was hoping to identify the outliers and substitute them with interpolated values.
4) From what I could find, the general consensus is that there are 5 ways to identify outliers: visually inspect the numerical values of the data, visually inspect the graphed data, Z-score, IQR, hypothesis tests.
I have, obviously, tried visual inspection. That ensues "cutting off" the horns. Which I can do, but I want to exhaust other means first. Hypothesis tests are highly dependent on hypothesis, which in my case is almost impossible to make (if I say there is one outlier and iterate, then how do I know when to stop iterating). IQR is deemed superior to Z-score. So, I tried IQR at once: it just "capped" all the data: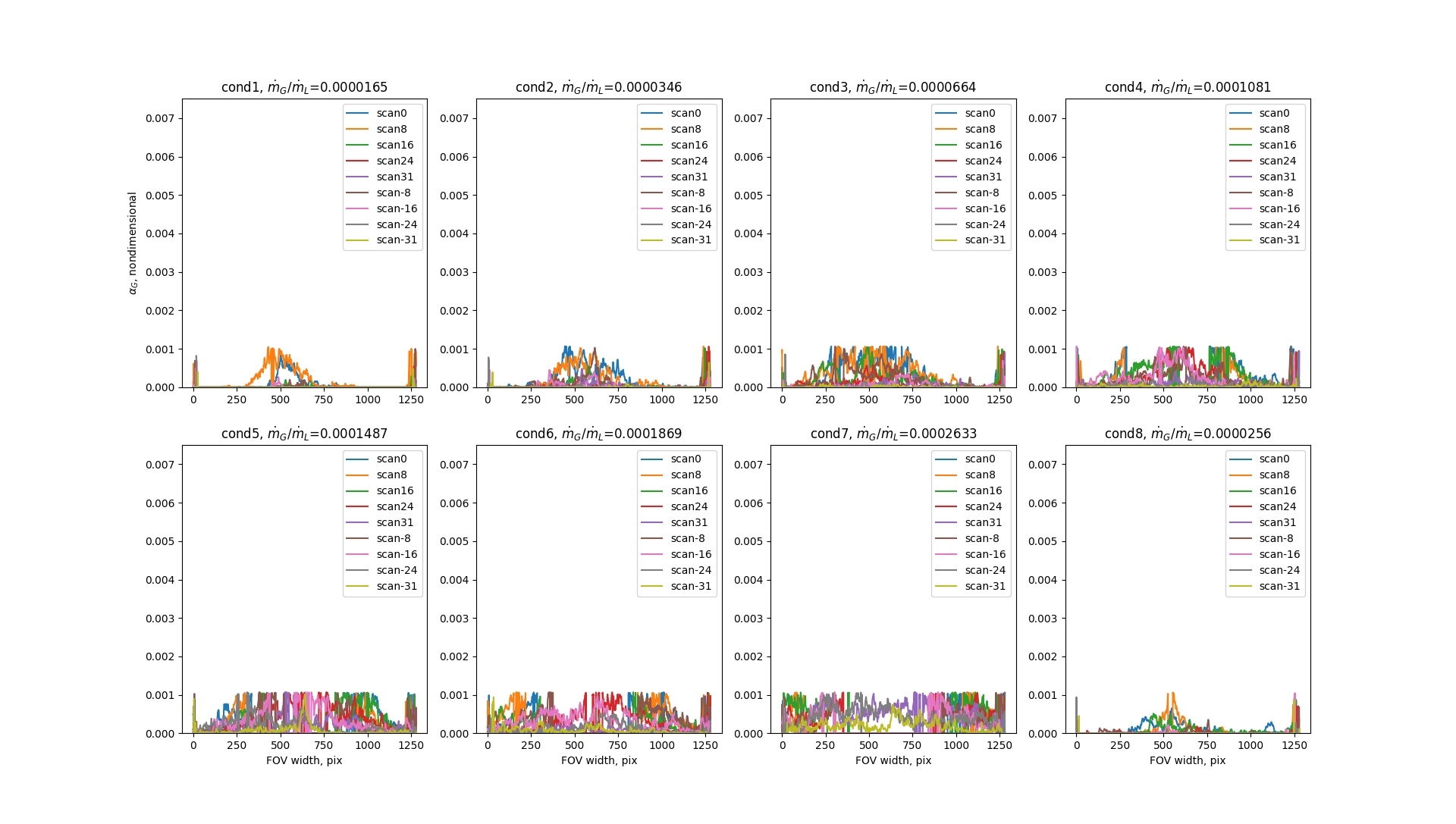
5) I was thinking about implementing IQR in a moving window, but before messing with that (and with other ideas of mine, like FFT or curve fitting) I would like to know is there a nice method that could identify those "horns" as outliers.
6) I used `matplotlib's` `plot` function to obtain the plots. I.e., it connected my data points with straight lines. Perhaps, I should've used `scatter` function. The bottom line is treat my plots as discrete data points, not as continuous lines.
 Ivan Nepomnyashchikh
·
2023-07-07T20:39:56Z (almost 2 years ago)
Ivan Nepomnyashchikh
·
2023-07-07T20:39:56Z (almost 2 years ago)